| 你的系统和普通 ChatGPT 问答最大的区别是什么? |
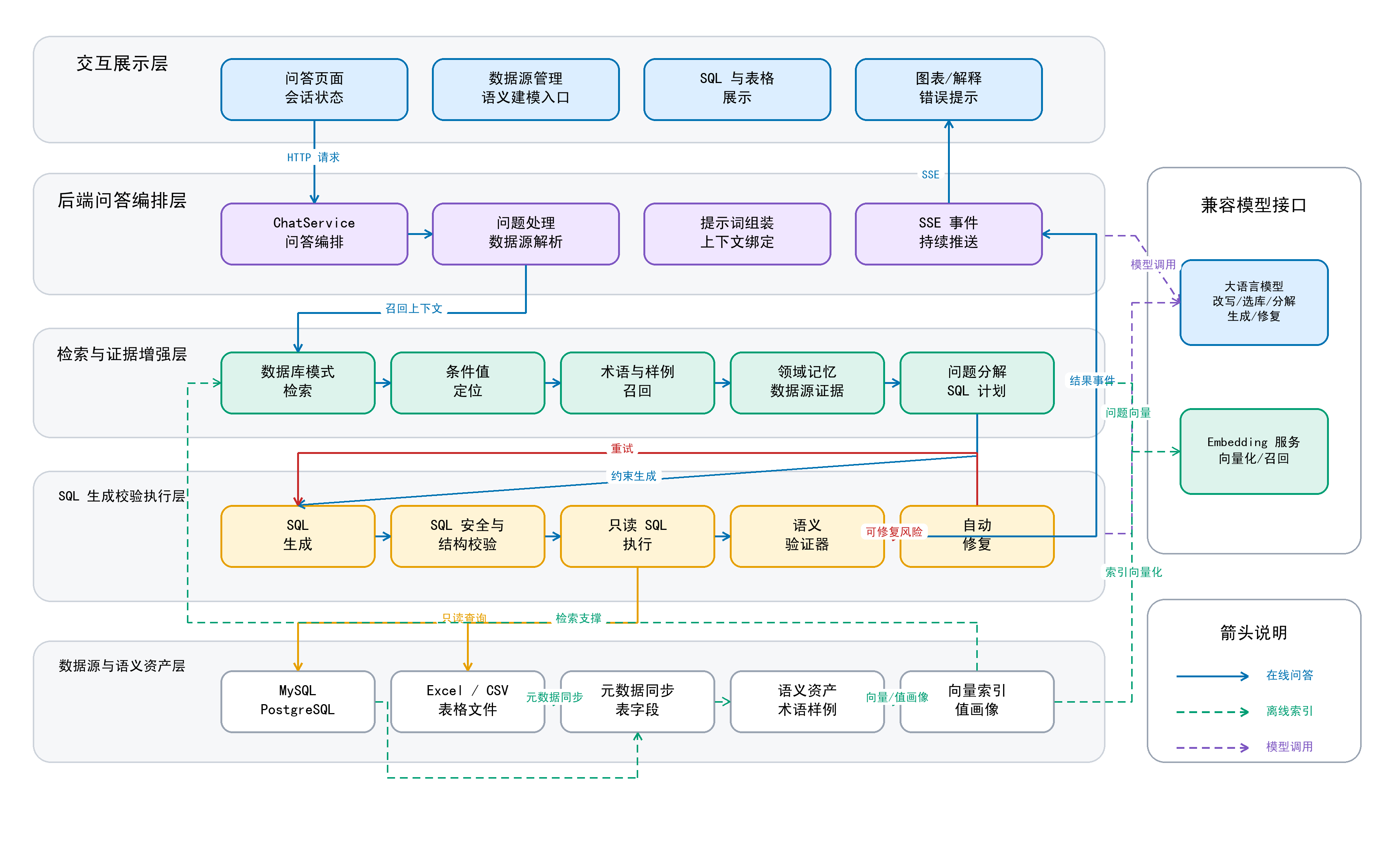
普通问答主要生成自然语言,本系统必须把问题落到当前真实数据源,先检索表字段和关系,再生成 SQL,并经过安全校验、执行和语义验证。 |
| 为什么说它不是传统 BI 平台? |
传统 BI 依赖预先配置好的指标和报表;本系统重点是动态 NL2SQL,把临时自然语言问题转成可执行查询,再按结果生成表格、图表和解释。 |
| 三类元数据为什么要分开讲? |
数据源与 Schema 画像约束结构,增强知识与证据补充业务语义,问答运行记录负责追踪和复盘;三者职责不同,混在一起会导致边界不清。 |
| 为什么要前后端分离? |
前端负责交互状态、阶段展示和结果渲染;后端负责数据源连接、模型调用、SQL 安全和执行。这个边界可以避免浏览器直接接触数据库和模型密钥。 |
| 系统启动时为什么还要做索引预热? |
Schema、术语、样例和领域记忆需要向量或索引支撑检索;后台 warmup 可以提前准备增强能力,同时通过初始化状态允许基础页面降级进入。 |
| 如何证明问答结果不是黑盒生成? |
系统会保存 ChatRecord 和 ChatLog,记录问题、SQL、执行结果、阶段日志、Prompt、模型响应和错误信息,因此可以按步骤复盘每次问答。 |
| 为什么数据源创建后要立刻同步元数据? |
因为 NL2SQL 不能只依赖连接配置,必须先知道当前数据源有哪些表、字段和注释;创建后自动同步可以保证数据源保存完就具备问答结构边界。 |
| Excel/CSV 为什么要转成本地 SQLite? |
这样文件型数据源可以复用数据库型数据源的连接、同步、预览、Schema-RAG 和 SQL 执行流程,不需要为文件单独实现一套问答链路。 |
表字段的 checked 开关有什么意义? |
checked 是人工可控的结构边界。未启用的表字段不会进入检索、值画像和 Prompt,可排除脏字段、敏感字段或业务无关字段。 |
为什么要维护 custom_comment,直接用数据库原始注释不行吗? |
真实库的原始注释经常为空、过旧或偏技术命名;custom_comment 用于补充业务语义,让检索文本和 Prompt 更贴近用户自然语言。 |
| 为什么表关系要前端手动建模? |
很多真实库没有显式外键,或外键不完整。手动关系建模可以把事实表和维表的 JOIN 路径固化下来,供关系补全、生成提示和 SQL 校验复用。 |
| 同步后的向量和值画像刷新失败会影响数据源管理吗? |
不会。同步后的 embedding、值画像、Domain Memory 刷新属于增强能力,代码中异常只记录日志,基础元数据同步和数据源维护仍然可用。 |
| 为什么不用字段级向量检索? |
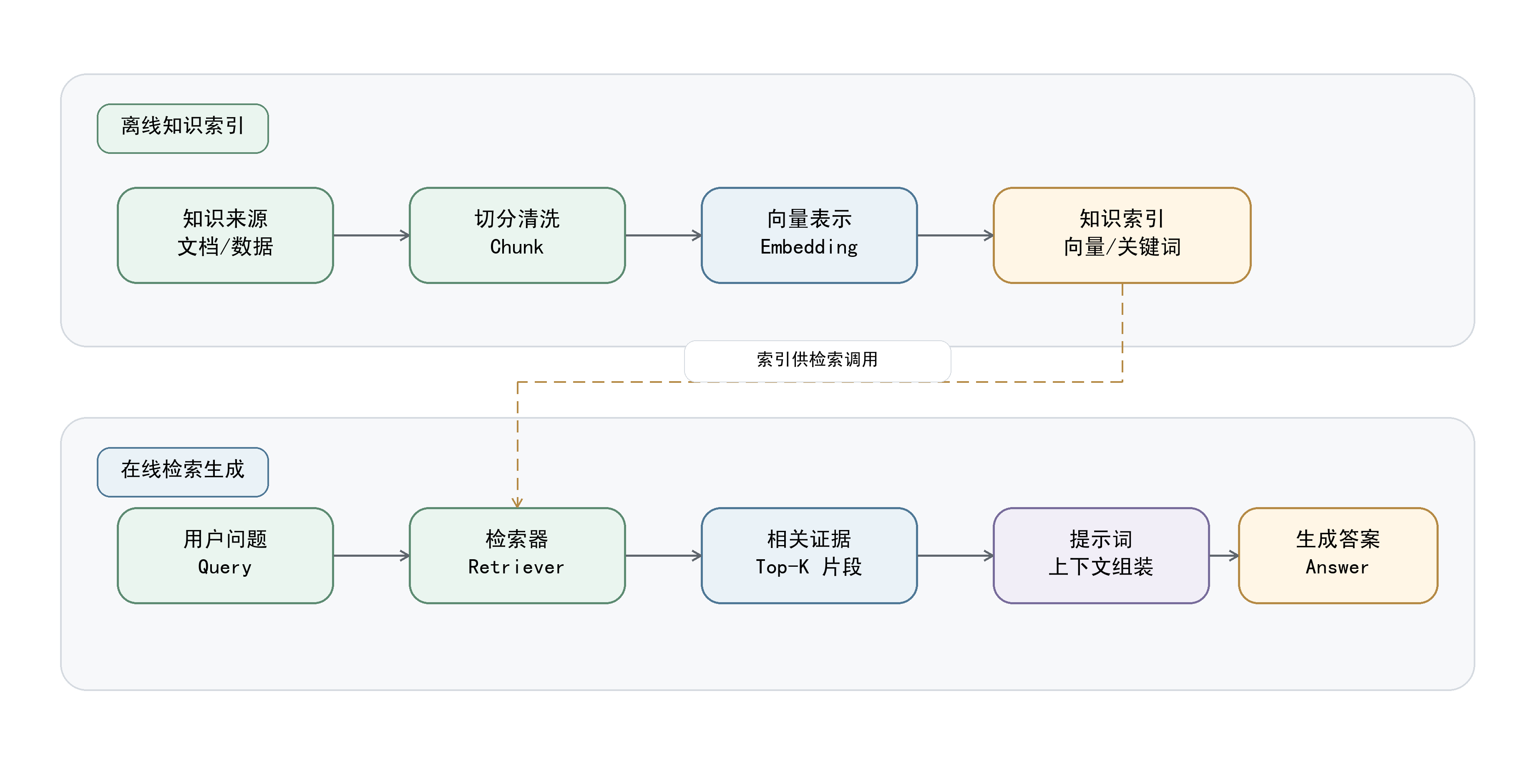
字段级召回容易拆散同表上下文,JOIN 路径也更难恢复;本系统先用表级召回保结构完整,再通过字段证据和关系补全细化。 |
| embedding 不可用时系统会不会瘫痪? |
不会。代码会退化为 keyword_fallback,保留关键词和启发式召回,数据源管理与基础问答仍可运行。 |
| 关系补全会不会乱补表? |
显式关系优先;无显式关系时才基于 ID 命名推断,并用问题相关性评分和补表上限控制范围。 |
| 检索证据会不会强迫模型选错表? |
不会。Prompt 里明确说明 direct-hit 只是候选,不是硬约束;只有高置信且有强 grounding 标签时才给 top1 preference。 |
retrieved_tables 和 selected_tables 有什么区别? |
retrieved_tables 是直接召回命中的表,selected_tables 是关系补全后的最终表集合;后者可能包含为了 JOIN 必须补入的桥接表。 |
为什么 Schema-RAG 要过滤 checked=True 的表字段? |
这是人工元数据边界。管理员未启用的表字段不会进入候选集,避免脏字段、敏感字段或业务无关字段干扰模型生成。 |
| Value Grounding 和 Schema-RAG 的区别是什么? |
Schema-RAG 解决“查哪些表字段”,Value Grounding 解决“问题里的实体值落在哪个真实字段取值上”;前者给结构边界,后者给 WHERE 值证据。 |
| 为什么 Value Grounding 不直接生成 SQL? |
它只提供候选过滤条件和列范围提示,最终是否使用仍由 SQL 生成、计划、校验和语义验证共同决定,避免把不确定值证据当硬规则。 |
| 强值证据的判定标准是什么? |
代码中把 exact 或 db_exact 且置信度不低于 0.99 的候选视为强证据;它会产生 strong tables,并影响 Schema 补表、Guard 和语义验证。 |
| 为什么还要 DB 等值查找,采样画像不够吗? |
采样画像有数量上限,目标值可能没被采到;DB 等值查找只对适合的短语做大小写无关精确查询,用来补回画像样本未覆盖但真实存在的值。 |
| 日期和数值字段为什么只记录范围? |
日期和数值取值空间通常较大,枚举式采样意义不大;记录 min/max 可以提示模型合法范围和时间边界,又不会把大量连续值塞进 Prompt。 |
| Value Grounding 失败会不会让问答失败? |
不会。它是增强能力,未命中或关闭时 Prompt 块为空,主链路仍依赖 Schema-RAG、术语、样例和 SQL 校验继续执行。 |
| 为什么知识增强层要拆成术语、样例、Domain Memory 和 Evidence? |
因为它们解决的问题不同:术语解释业务词,样例提供 SQL 写法,Domain Memory 保存长期业务片段,Evidence 约束指标口径;混成一个文本块会丢失优先级和来源。 |
| 术语召回会不会让模型使用不存在的字段? |
不会。术语只解释业务含义,最终字段仍必须来自 M-Schema;Prompt 和 Guard 都要求不能臆造表字段。 |
| 全局 SQL 样例为什么不能直接复用表名字段名? |
全局样例跨数据源使用,只能提供查询结构和写法模式;代码会把它标成 pattern_only 并写入不得复用表字段名的约束。 |
| Domain Memory 和 datasource evidence 有什么关系? |
datasource evidence 是人工维护的业务证据;Domain Memory 会把 evidence、表注释、字段注释和关系说明统一转成可检索片段,是 evidence 的长期检索化形态之一。 |
| 问题级 evidence 和数据源级 evidence 冲突时怎么办? |
问题级 evidence 优先,因为它是本轮问题的临时补充;但两者都不能违反当前 Schema 和真实字段语义。 |
| Retrieval Evidence 为什么是保守注入? |
它只解释 Schema-RAG 的 direct-hit、关系补表和 ranking 依据,不替代表选择;只有 top1 明显领先且有强 grounding 标签时,才给出高置信偏好。 |
| 问题改写为什么不每轮都调用大模型? |
改写只在存在历史问答时才有意义;无历史、功能关闭或模型不可用时直接跳过,避免为了简单单轮问题增加成本和改写风险。 |
| 改写后的问题会不会覆盖用户原问题? |
不会。系统同时保留原始问题和 effective_question,日志里能看到是否 applied、skip_reason 和模型原始输出,便于复盘。 |
| 问题分解为什么默认偏保守? |
分解对复杂题有帮助,但简单题可能改变输出粒度;所以当前实现先用风险标签和白名单收缩范围,未命中时主链路直接生成。 |
| SQL Experience 和 SQL 样例有什么区别? |
SQL 样例是“相似问题怎么写”的 few-shot 参考;SQL Experience 是“历史上哪里容易错”的规则提醒,强调错误边界和自检。 |
| 为什么 SQL Experience 不用向量检索? |
经验规则数量和结构更适合可解释规则打分;代码会记录类别、关键词、Schema 特征和错误信息命中的 reasons,便于控制和排查。 |
| 成功 SQL 为什么不能直接进入样例库? |
可执行不代表口径一定正确。系统先进入 SQL 经验候选队列,人工审核通过后才导入正式 DataTraining,避免污染样例库。 |
| SQL Plan 和数据库执行计划有什么区别? |
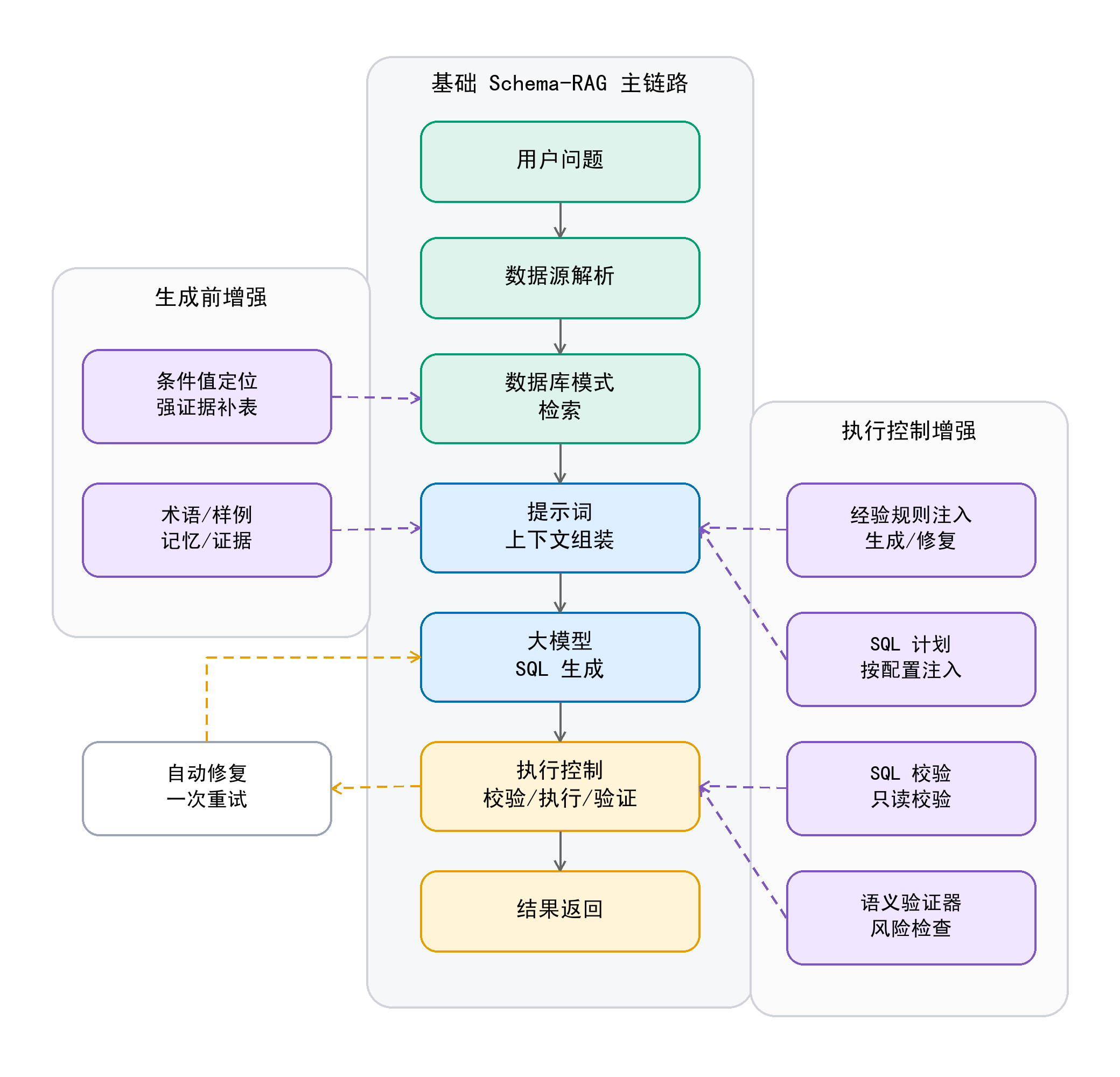
数据库执行计划服务于执行代价优化;本系统的 SQL Plan 服务于生成前语义约束,描述必要表、过滤条件、指标口径和结果形态。 |
| 为什么 SQL Plan 不直接生成 SQL? |
直接生成 SQL 会把计划层变成第二个模型生成器;当前实现只用本地规则产出结构化约束,降低延迟,也避免和 LLM 的生成口径互相漂移。 |
shadow、soft、enforced 有什么区别? |
shadow 只记录计划不注入 Prompt;soft 和 enforced 在达到置信度阈值后注入,区别在于答辩解释上 soft 更偏提示,enforced 更偏强约束。 |
| SQL Plan 的置信度能当概率解释吗? |
不能。它是启发式明确度分数,过滤条件、指标、目标列和结果形态会加分,未解决项会扣分,用于判断计划是否值得注入。 |
| Prompt 为什么强制模型输出 JSON? |
后端需要稳定解析 SQL、表名、图表类型和失败原因;如果模型返回自然语言混排文本,后续 Guard、执行、前端展示和日志复盘都会不稳定。 |
| Prompt Override 会不会破坏默认生成约束? |
覆盖能力受 PromptOverrideProfile.enabled 和非空字段控制;未启用或字段为空时仍走默认 YAML 模板,主链路上下文契约和解析对象保持不变。 |
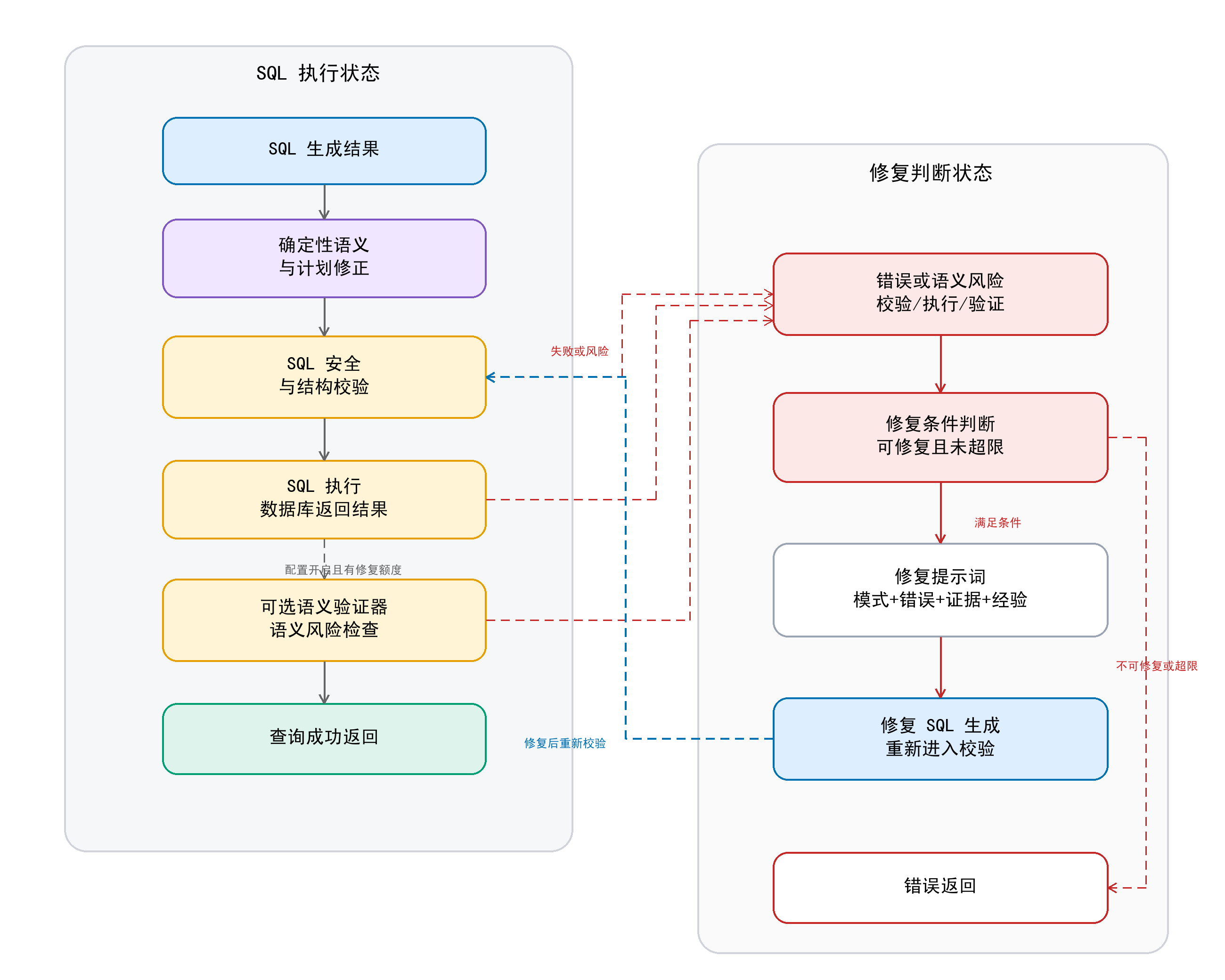
| 为什么有了 SQL Guard 还要语义验证? |
Guard 主要回答“能不能安全执行、表字段是否越界”;语义验证回答“执行结果是否可能答偏”。能执行不等于答对,所以两层检查不能合并。 |
| 自动修复会不会把错误 SQL 越修越乱? |
修复受错误类型和重试次数限制,默认最多 1 次;修复 SQL 还要重新经过 Guard、执行和语义验证,因此不是无边界重写。 |
| 为什么修复阶段要裁剪 Schema? |
修复时如果继续给全量上下文,模型容易被无关表干扰;系统优先围绕失败 SQL 实际引用表、direct-hit 表和关系邻居构造 focused schema。 |
| 语义验证器为什么可能在简单问题上有副作用? |
语义验证依赖保守规则,复杂问题收益更明显;简单问题中额外检查可能触发过度修复或改变输出列形态,所以论文中也把它解释为适合高风险场景触发。 |
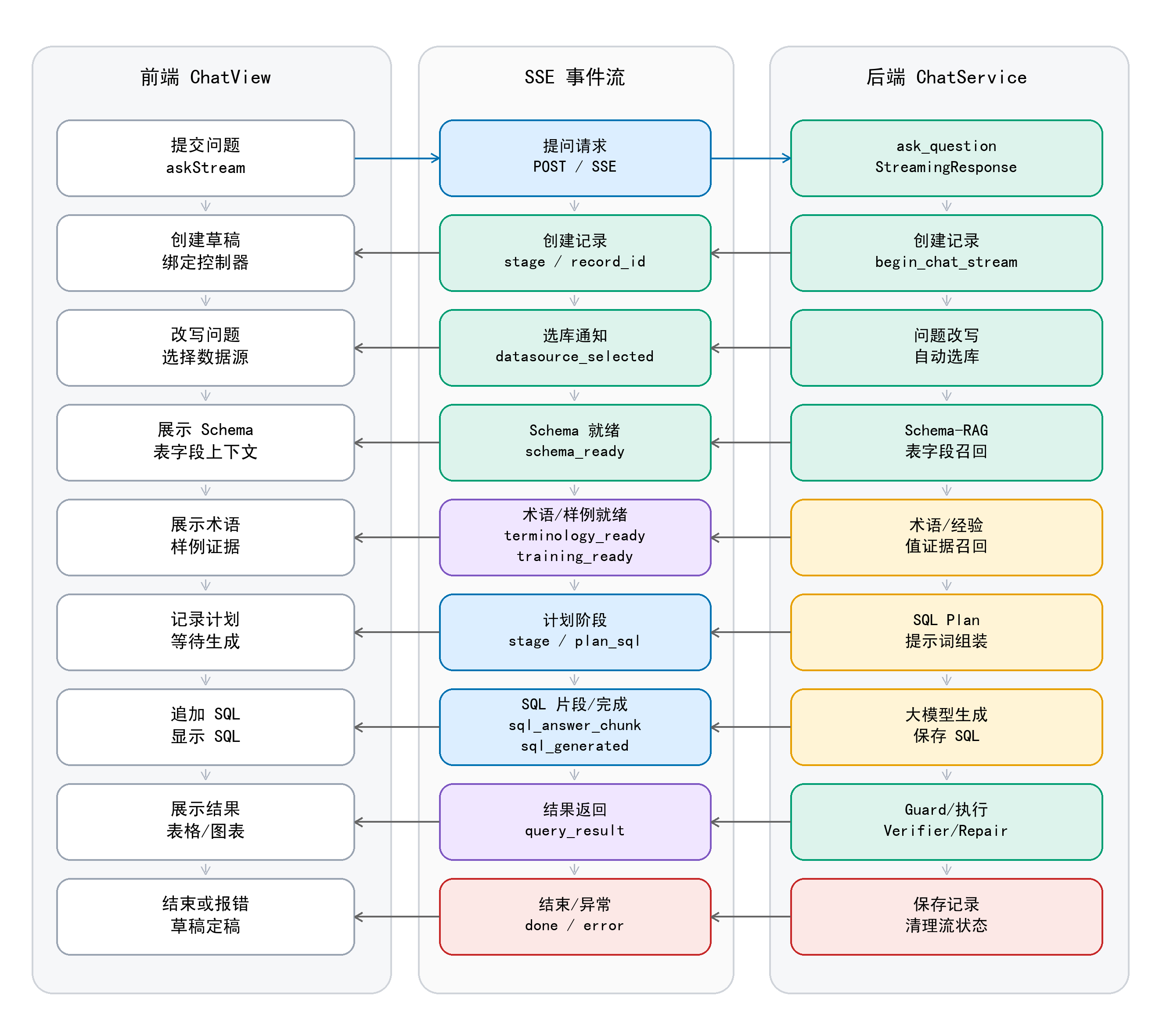
| 为什么主链路用 SSE,而不是 WebSocket? |
本系统是“客户端提交一次问题,服务端持续返回阶段状态和结果”的单向推送场景;SSE 基于普通 HTTP,足够承载阶段事件,也比 WebSocket 更轻。 |
| 为什么不直接等后端结束后一次性返回? |
问答链路很长,包含检索、生成、校验、执行、修复等阶段;SSE 可以把阶段状态实时推给前端,避免用户面对长时间空白等待。 |
为什么每条事件都要带 record_id? |
record_id 是本轮问答的稳定锚点,前端可把事件合并到正确草稿,后端也能把日志、SQL、结果和错误统一落到同一条记录。 |
| 为什么图表和解释不放在主 SSE 流里一起生成? |
主流优先保证 SQL 与查询结果闭环;图表、解释和推荐追问属于结果后处理,按需生成可以减少主链路阻塞。 |
| 图表生成失败会不会影响已经查出的结果? |
不会。图表是记录级可选后处理,失败时会回退为本地图表或表格配置;主结果表、SQL 和执行状态都已经落库。 |
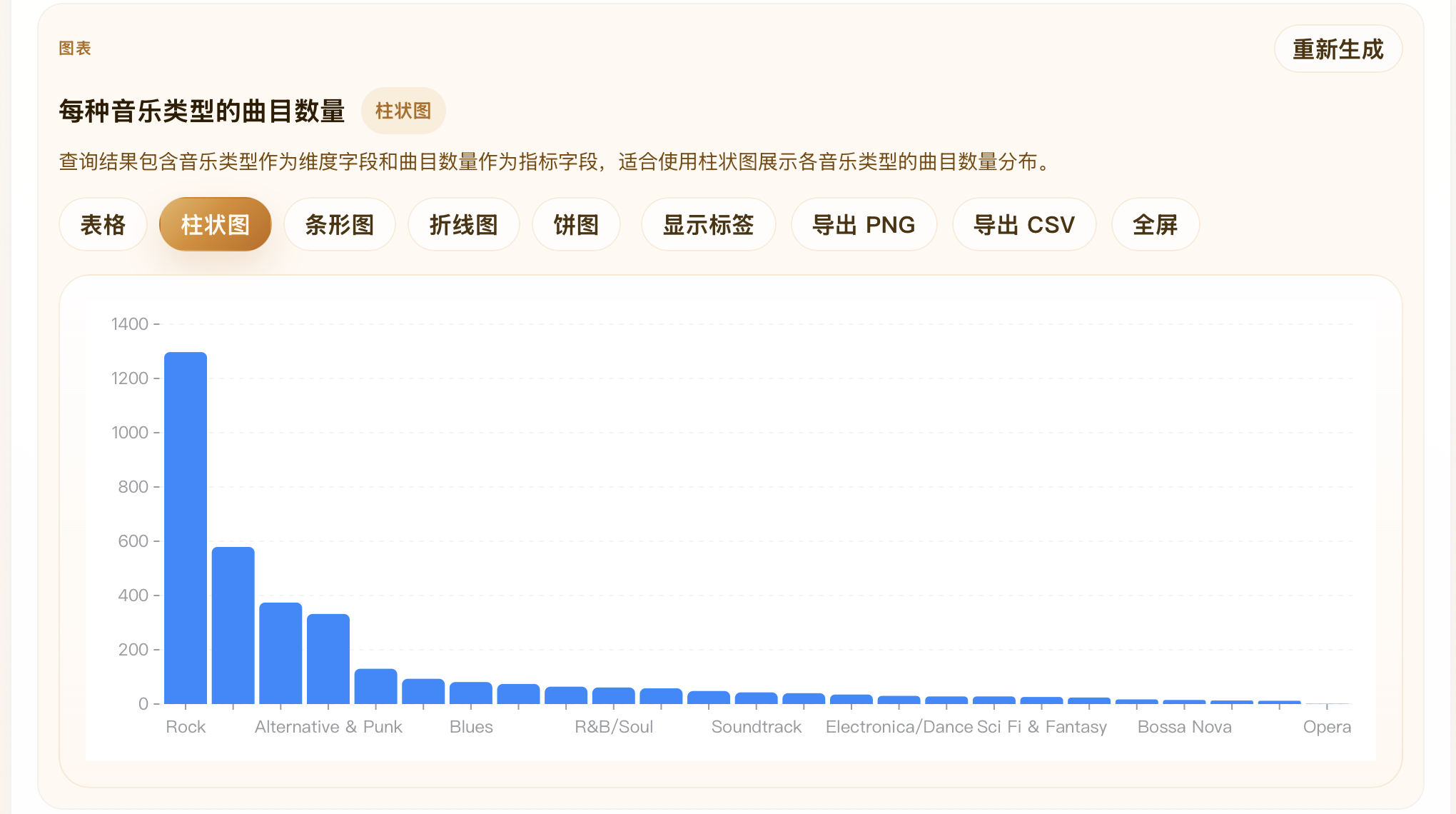
| 为什么图表字段还要做规范化校验? |
模型可能返回大小写不一致或不存在的字段名;后端和前端都会把坐标轴字段映射回真实结果字段,映射失败就回退,避免图表引用幻觉字段。 |
| 解释生成会不会编造业务结论? |
Prompt 明确要求只解释当前问题、SQL 和结果预览,不编造背景;模型失败时只用行数和字段名生成兜底说明。 |
| 起始推荐问题和追问推荐有什么区别? |
起始推荐面向数据源空状态,基于 Schema 摘要或手工配置;追问推荐面向某条已完成记录,基于原问题、SQL、结果字段、结果预览和最近问题。 |
| 为什么 fallback 推荐不写入数据库缓存? |
fallback 是当前请求的保底结果,不一定代表高质量业务推荐;代码只把 LLM 成功生成的自动 starter 或记录级追问写入缓存,避免污染后续展示。 |
| 空结果时为什么推荐“恢复型追问”? |
0 行结果通常说明时间、枚举或筛选条件过严;系统优先推荐确认可用范围、放宽条件和查看总体分布,而不是继续沿着失败条件下钻。 |
配置为什么要集中到 Settings,不能各模块自己写默认值吗? |
集中配置能保证实验可复现、线上行为可解释;如果默认值散落在各服务里,增强开关、召回数量、修复次数和 token 预算很难统一控制。 |
| 模型配置从哪里来,数据库设置和环境变量谁优先? |
有数据库会话时优先读取当前激活的模型设置;如果没有激活设置或读取失败,再回退到 settings.DEFAULT_LLM_* 环境配置。 |
| Embedding 配置缺失时系统会不会启动失败? |
不会。Embedding 可用性由门控函数判断,不可用时刷新函数会保存最新文本快照、清空旧向量,并让在线检索退回关键词和启发式排序。 |
| 为什么索引 warmup 不阻塞系统入口? |
因为索引是增强能力,不是数据源管理和基础问答的硬前置。启动时先初始化数据库和默认数据,再后台预热索引,前端通过状态接口展示 degraded 或 ready。 |
| warmup 失败后用户怎么知道该怎么办? |
状态接口会返回 degraded、summary、recommended_action、last_error 和离线预构建命令;前端初始化页和降级横幅会展示这些信息。 |
| 离线预构建脚本解决什么问题? |
它用于部署前、答辩演示前或 warmup 失败后同步补齐表向量、数据源向量、术语、样例和推荐缓存,降低冷启动和现场等待风险。 |
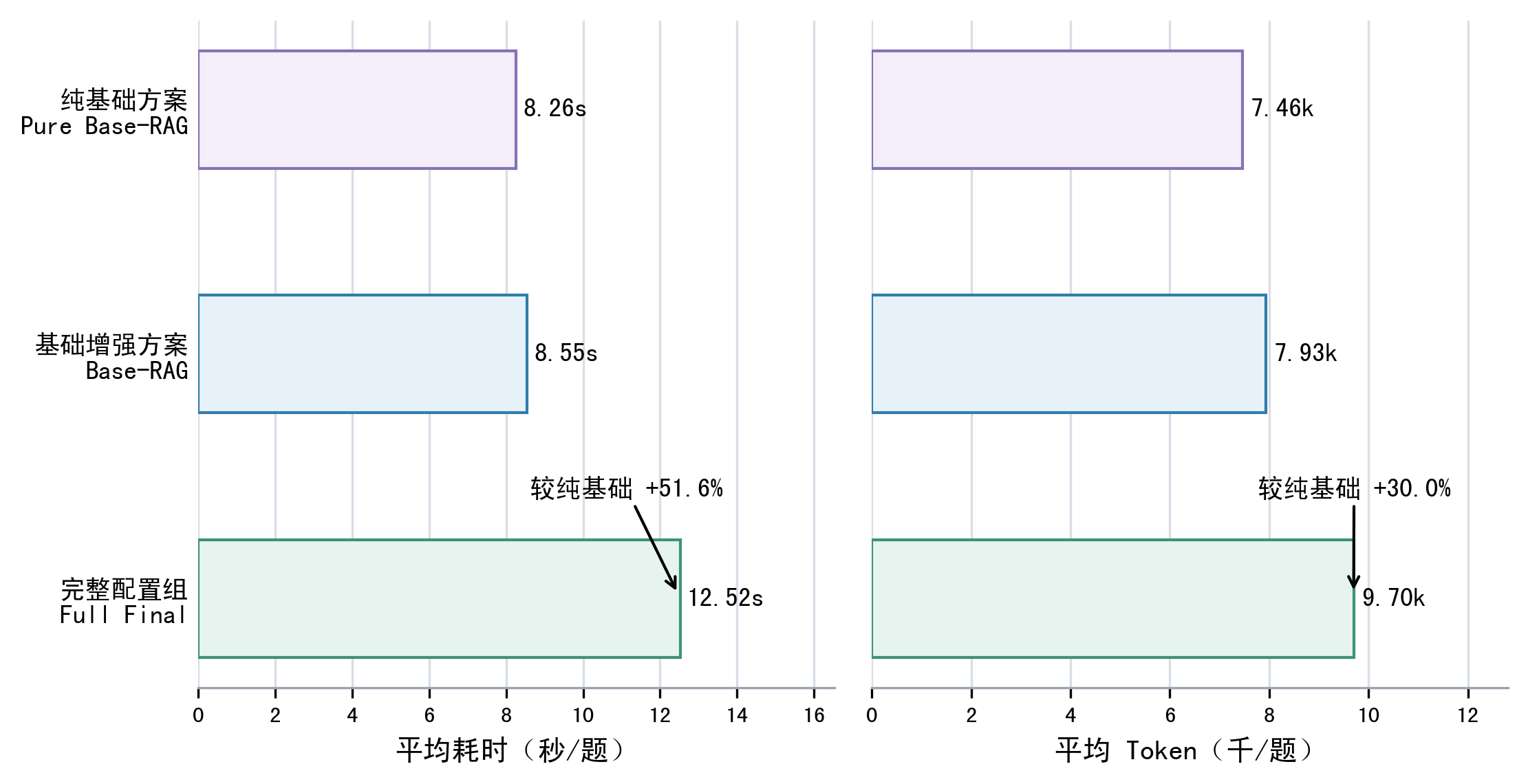
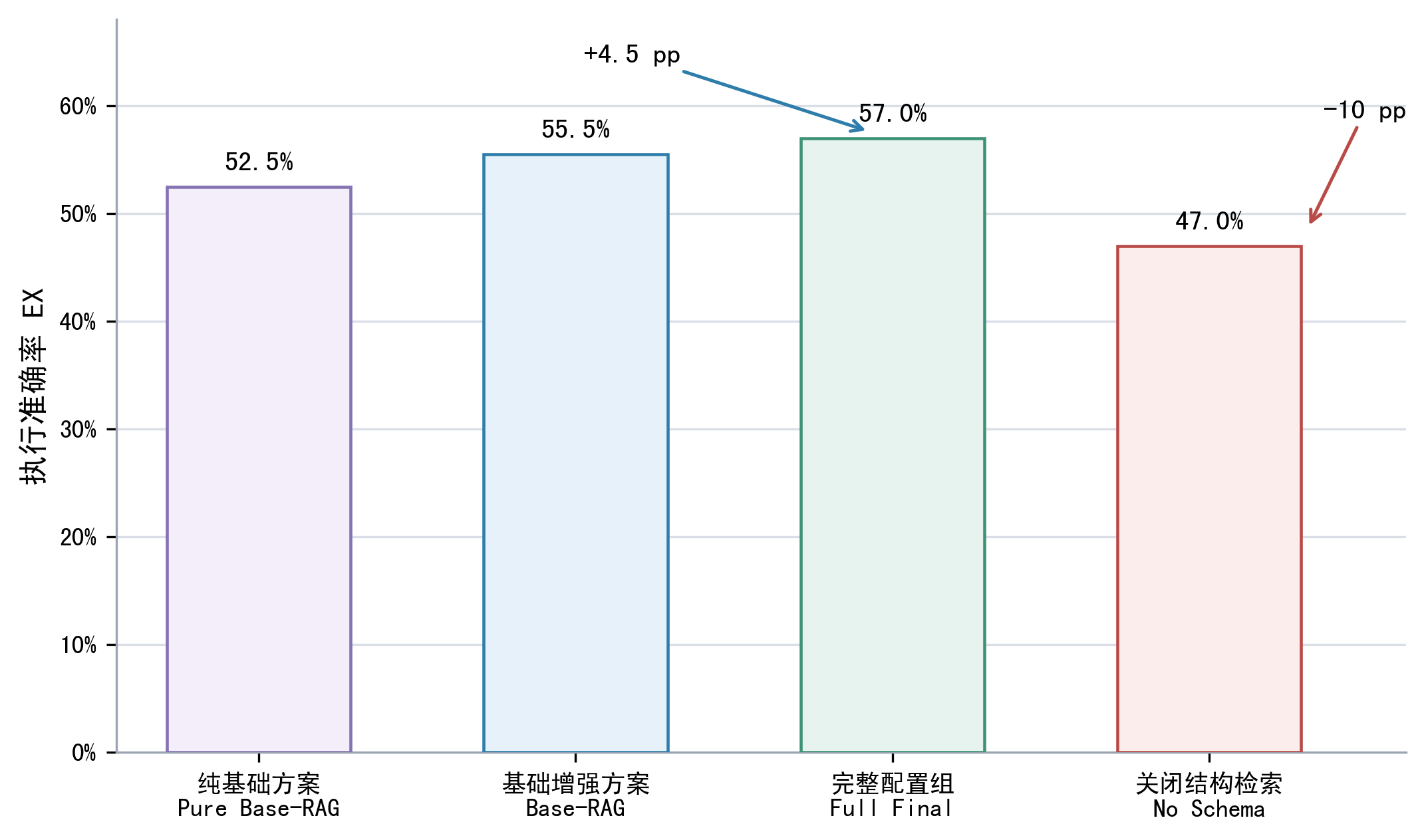
| 为什么完整配置组更慢但仍然有意义? |
完整配置组增加术语、样例、值证据、SQL Plan、语义验证和修复等上下文,Token 和模型耗时会上升;它的意义在于覆盖复杂问题和能力上限,而不是无条件替代轻量链路。 |
| 为什么论文主指标用 EX,而不是 SQL 文本完全一致率? |
因为同一个问题可能有多条语义等价 SQL,文本不同但执行结果相同仍应判为正确;EX 更贴近用户关心的“查出来的结果对不对”。 |
| BIRD 和 Spider 分别证明什么? |
BIRD 主要验证真实数据库值、外部证据和复杂业务约束下的执行效果;Spider 作为补充,验证跨数据库结构泛化,不能把两者混成同一种结论。 |
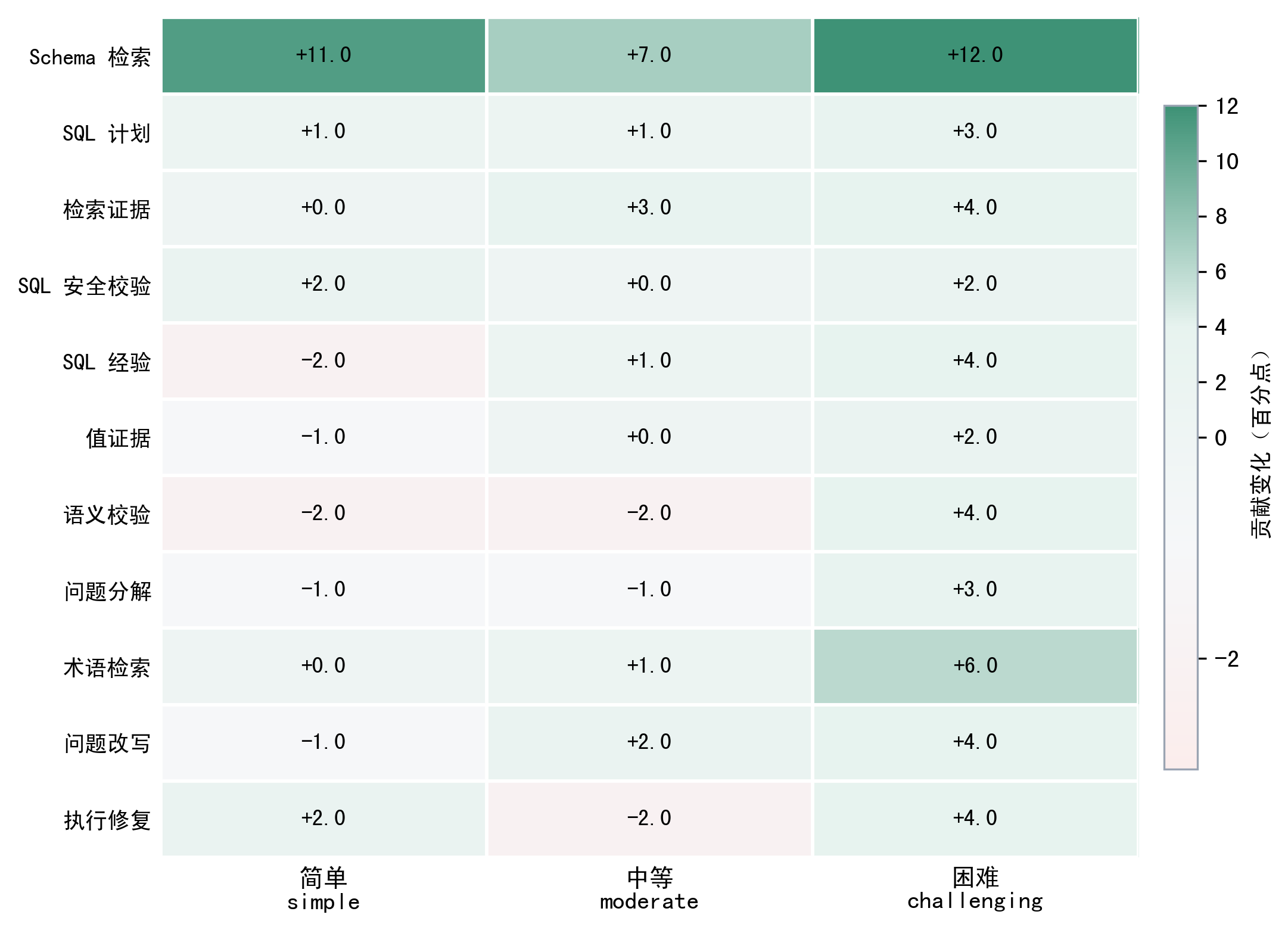
| 为什么 No Schema Retrieval 组很关键? |
它只关闭数据库模式检索,其他增强保持完整配置;如果该组明显下降,就能说明结构召回是基础约束,不是被值证据或修复轻易替代的模块。 |
| Full Final 只比 Base-RAG 高 1.5 pp,怎么解释? |
要谨慎解释为小幅增量,不能夸大成稳定大幅提升;它说明完整增强在当前 200 条样本上有收益,但还需要结合难度分层和消融说明收益主要来自复杂题。 |
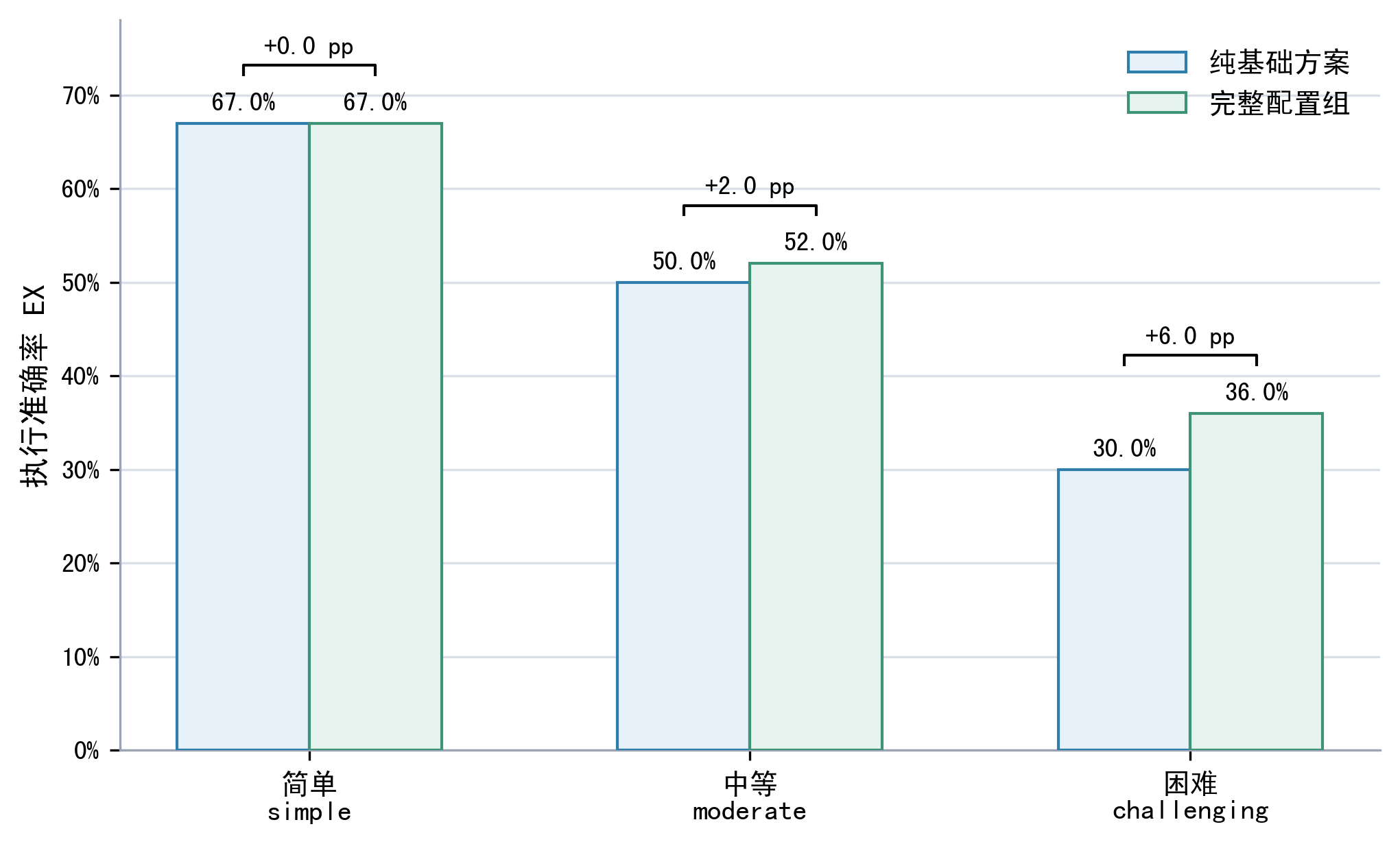
| 为什么增强策略在 simple 样本上可能没有收益甚至负贡献? |
简单题通常只需要少量表字段,基础 Schema-RAG 已足够;额外验证、修复或证据注入可能改变输出列粒度或增加噪声,所以增强更适合按风险触发。 |
| 消融实验里的模块贡献能直接相加吗? |
不能。模块之间有依赖和交互,Full-NoModule 只是近似观察关闭单个模块后的变化,必须结合难度、样本类型和触发条件解释。 |
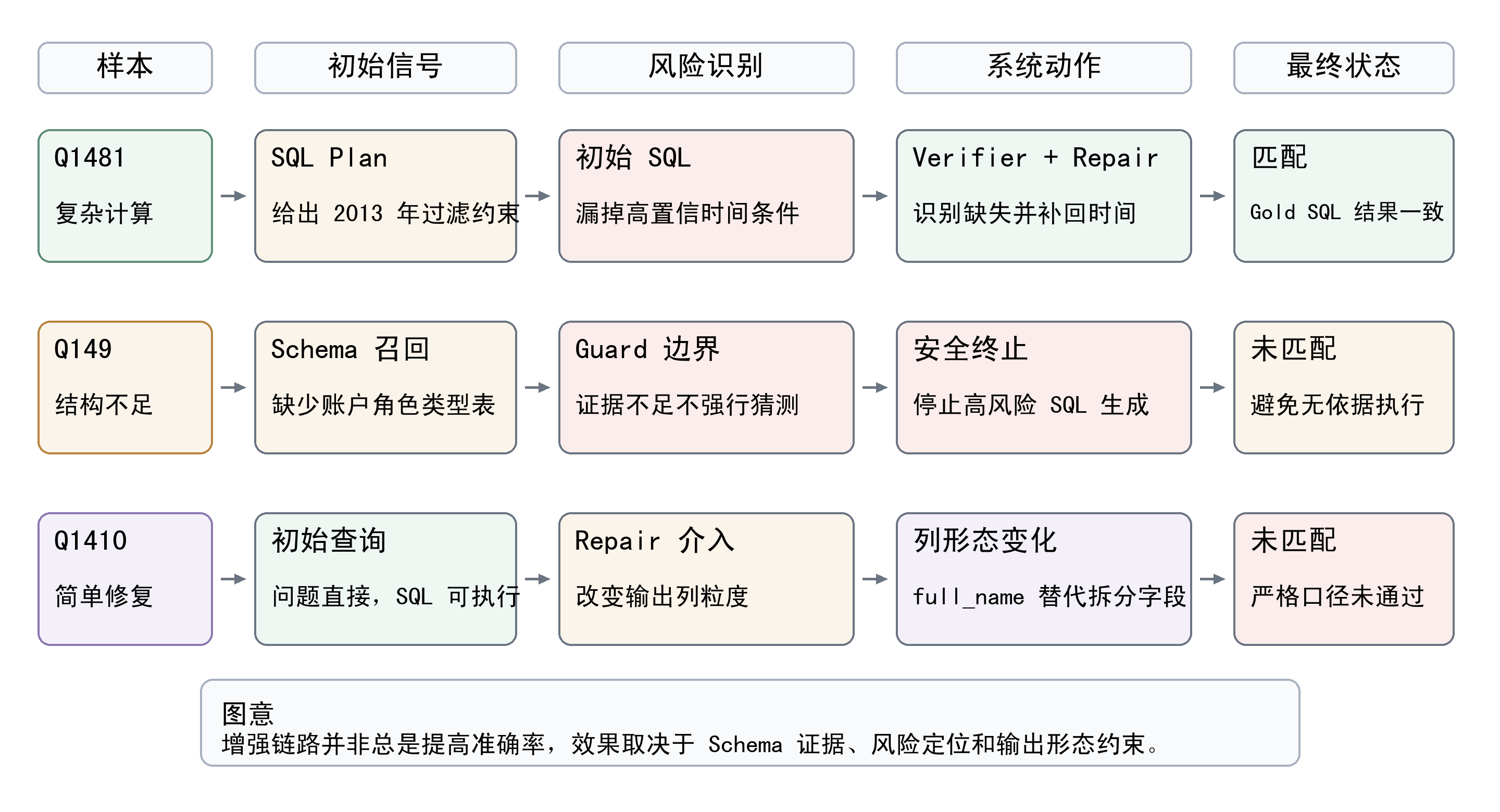
| 典型样本分析为什么重要? |
平均指标只能说明总体变化,典型样本能解释变化原因:有的样本被语义验证修正,有的因结构证据不足被阻断,也有简单题被过度修复。 |
| 运行成本主要花在哪里? |
主要花在模型调用和长 Prompt,不是数据库执行。论文日志显示 SQL 生成通常是数秒级,预测 SQL 执行只有几十毫秒量级。 |
| 论文里的 13 张图答辩时应该按什么顺序讲? |
先讲系统架构图定边界,再讲 RAG 和 Schema-RAG 控制流说明方法,随后讲修复状态机和 SSE 证明工程闭环,最后用功能截图、BIRD/Spider/消融/成本图证明效果与边界。 |
| 功能测试截图能不能作为论文证据? |
可以,但证据类型不同。功能截图证明系统链路和交互可用,不能替代离线 EX 指标;论文中应把它作为工程实现与功能闭环证据,指标结论仍看 BIRD、Spider 和消融实验。 |
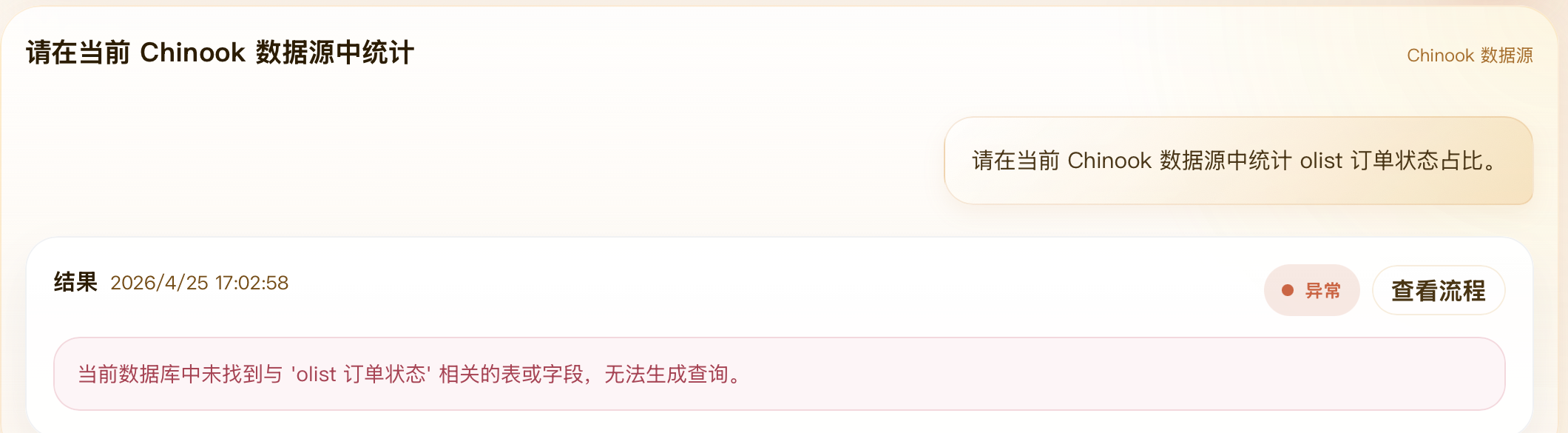
| 错误领域问题截图想证明什么? |
它证明系统不是无边界生成器。问题脱离当前数据源时,系统应该返回可解释错误或拒答,而不是编造表字段和 SQL,这对应 Guard、主链路错误收敛和前端错误展示能力。 |
| 多表 JOIN 功能截图想证明什么? |
它证明自然语言问题可以经过 Schema-RAG 召回、关系补全、SQL 生成、执行和结果渲染变成真实多表查询结果,重点支撑“关系补表不是纸面设计”。 |
| 算法 1 的输入输出如果老师要求现场说清楚,怎么答? |
输入是问题、数据源、启用表字段、向量快照和关系边;输出是 focused schema、直接召回表、关系补全后的最终表、外键关系和排序证据。核心就是先召回,再补 JOIN 路径。 |
| 算法 2 为什么要把值画像和 DB exact lookup 结合? |
值画像快、可缓存,但采样可能漏值;DB exact lookup 慢一些但能补真实存在的精确值。两者结合是为了在成本可控前提下提高 WHERE 条件落点准确性。 |
| 算法 3 为什么不是简单 try-catch 重试? |
它不是盲目重试,而是先分类错误来源:只读越界、表字段不存在、JOIN 风险、执行错误、语义偏差。只有可修复且未超过次数上限时才构造聚焦上下文修复。 |
| 算法 4 和系统架构图有什么区别? |
架构图讲模块边界和数据流,算法 4 讲一次请求的时间顺序。前者回答“系统由什么组成”,后者回答“用户点发送之后每一步怎么走”。 |
| 提示词目标公式是不是只是装饰? |
不是。公式把 Prompt 的组成变量显式化:Schema、知识、值证据、检索证据、计划、历史、约束和反馈都进入生成条件,工程上对应 PromptBuilder 与 ChatService 的上下文拼装。 |
混合召回公式里的 H(T_i,q) 怎么解释? |
它是启发式加分项,用来补足向量和关键词难覆盖的业务信号,例如表名/字段名强命中、值证据强关联、关系表必要性等,不是不可解释的模型参数。 |
SQL Plan 公式里的置信度 c 为什么不能当概率? |
因为它不是统计训练得到的概率,而是计划完整度和明确度分数。它只用于判断计划是否适合注入 Prompt,以及在日志里解释计划约束强弱。 |
| 为什么 EX 不看 SQL 文本完全一致? |
NL2SQL 存在多条等价写法,比如子查询和 JOIN、不同别名、条件顺序不同都可能得到同样结果;EX 以执行结果为准,更贴近用户关心的答案正确性。 |
| 消融热力图如果出现负贡献,是否说明模块没用? |
不能简单这么说。负贡献可能说明模块在某些样本上引入噪声或过度约束,结论应是“需要按风险触发和按场景开关”,而不是把模块完全否定。 |
| 成本图如何避免被老师追问“太慢不实用”? |
要承认完整增强更慢,然后强调系统支持分层配置:简单问题走轻量链路,复杂或高风险问题再启用语义验证、修复和更多证据;成本图正是用来说明这种工程取舍。 |
| 如果老师问代码和论文算法是否完全一一对应,怎么回答? |
论文算法是工程流程的抽象表达,不会逐行等同代码;但关键输入输出和控制阶段一一对应,例如 Schema-RAG 对应 schema_retrieval.py,Value Grounding 对应 value_grounding.py,修复链路对应 Guard、Executor、Verifier、Fixer 和 ChatService。 |
| 前端如何避免 SSE 半包解析失败? |
前端维护 buffer,用空行切出完整事件块,未完整的 rest 保留到下一次读取,只有完整 data: 块才 JSON parse。 |